Using EXIF data to improve photography
There is so much camera gear out there. It’s hard to know what you want - distinguishing gear that you want because it’s cool and gear that you want because it’s useful (but still cool) can be very difficult.
When I bought my new camera I also got the kit lens. It’s a great lens, much better than a typical ‘kit lens’, but at the time I was worried that I’d miss having the longer focal lengths of the 24-105mm lens I was leaving behind. Like all decisions, this dilemma could be helped by having more information. How do I usually take photos? Which lens did I use the most? What’s my favourite focal length?
EXIF data
Every digital photo includes information embedded in the file about how each picture was taken, called EXIF data. The EXIF data for a given photo depends on the camera used, but generally includes things like the camera make and model, shutter speed, focal length, aperture, data and time of capture, even the location of the photo. Some people choose to strip their photos of EXIF data if they’re uploading them to the internet for privacy reasons.
So what?
With Python we can pull back the covers and take a look at the EXIF data for any photo. There are web services that offer EXIF viewing, but for this purpose Python is better for three reasons: it’s faster, I keep hold of my own data, and we can tailor the analysis to our needs.
Using Python
Exifread is a Python module that extracts EXIF metadata from jpg and tiff files. It’s simple, and plenty for our purposes. The main process_file method returns a dictionary of each of a picture’s EXIF tags and the corresponding value for each tag.
Using Exifread we can write a simple Python script to loop through the EXIF data for every photo on in my ‘Pictures’ folder. These photos only date back to 2016 and only includes the photos I deemed good enough to export. Even though this is only a sample, it might actually be more useful to only look at photos that are above a certain ‘quality’ threshold - they’re the photos I want to take more of!
The Juypter notebook for this analysis is on Github - the full detail of the code is there. I might skip some of it for this post. Looking at an example image, we can see that one Canon raw (.cr2) file contains 161 EXIF tags. These look to be split into 3 categories:
- Standard EXIF data about time, photo dimensions, gear, settings, etc.
- Image / IDF information more focused on pixel-level data: sampling, compression, resolution, etc.
- Maker Notes: More detailed proprietary camera settings included by Canon
We definitely don’t need all 161 tags. Instead, we can select only the few we want to look at, contained in the tagShortlist dict. Then we can loop through the directories we’re looking and extract those tags from each photo.
tagShortlist = {
'EXIF FNumber':'Aperture',
'EXIF ExposureProgram': 'Exposure Mode',
'EXIF DateTimeOriginal':'Date',
'EXIF ExposureTime':'Exposure',
'EXIF FocalLength':'Focal Length',
'EXIF ISOSpeedRatings':'ISO',
'MakerNote LensModel':'Lens'}
def photoWalk(photoPath, EXIFtags):
# Walks through subdirectories in photoPath and extracts selected
# EXIF tags based on the supplied dict EXIFtags for each photo file. Returns a dataframe.
photoData = pd.DataFrame(columns=list(EXIFtags.values()))
for subdir, dirs, files in os.walk(photoPath):
for file in files:
f = open(os.path.join(subdir, file), 'rb')
tags = exifread.process_file(f)
# Check for non-photo files that have no EXIF tags
if len(tags) != 0:
# Create a dict of selected tags and values
values = {categories[x]:str(tags[x]) for x in list(EXIFtags.keys()) if x in tags}
photoData = photoData.append(values, ignore_index=True)
return photoData
photoData = pd.DataFrame()
for year in range(2016,2020):
photoPath = os.path.join(os.path.expanduser('~'), "Pictures", str(year))
yearData = photoWalk(photoPath, tagShortlist)
photoData = photoData.append(yearData)
After some cleaning, we now have a useful set of data to examine.
My habits
The data is now clean enough. Off the bat it looks like we’ve got 549 photos, taken with an average focal length of 68.5mm and an average aperture of f/2.3. That focal length is about where I expected, but the average aperture is probably lower than it should be.
Focal Length
Depending on your needs, focal length is probably the primary criterion when picking a lens. Based on the data I clearly have preference for longer focal lengths. My average focal length (68.5mm) is on the low edge of telephoto range, but towards the high end of the range of the lenses in my collection. We can graph the distribution of focal lengths among the photos we’re analysing.
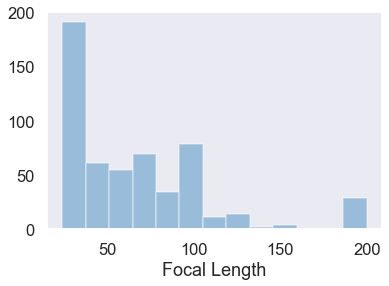
There are 3 lenses are included the above figure - one of them is a 35mm prime (which explains the massive spike on the left), and another (the 18-200mm) I no longer own. Those two can be excluded. The remaining lens is my second-hand 24-105mm f/4 workhorse. Just looking at that lens, the histogram looks a bit different.
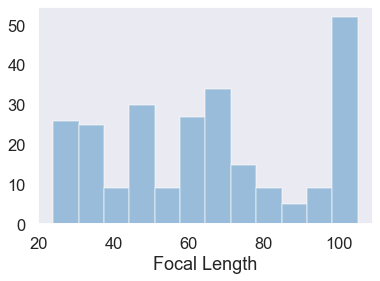
I think it’s safe to say I’m looking for a bit more zoom range - presumably that large right-hand column would be spread out along larger focal lengths if it wasn’t limited to 105mm. Maybe instead I should just let my feet do the zooming? There’s also a gulf between about 65mm and the 105mm edge. The trend appears looking only at photos from the 18-200mm lens, but extends the upper range to about 115mm. It seems like my eyes are dialed in to frame at either ~115mm or ~65mm, but not in between. There’s also an even larger gulf between 115m and the 200mm edge.
In his review of the Leica Q, Craid Mod talks about “edges” of the interface. A lot of my photos on zoom lenses are taken at this edge of lens’ zoom range.
And yet it’s easier to quickly turn the camera on into C mode than S mode because C sits at the “edge” of the interface. C is at the “top” of the screen. There is no precision required to choose C, but S — plopped in the middle — requires delicacy. Exactitude.
Apertures
Aperture is another important distinction between lenses. Lenses that can produce wider apertures can let in more light and provide a narrower depth of field, but are often less sharp at these settings. Typically camera lenses are at their sharpest around f/8 or about 3 f-stops from their widest aperture - lower f-stops start sacrificing sharpness for depth of field. In either case, f/2.3 is too low to average. I should stop hanging down in the low f-stops and improve my sharpness. I’ve written a bit more about how f-stops work here.
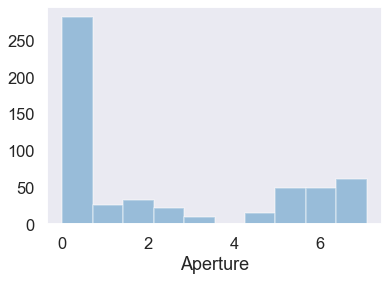
General Trends
With the data we can also look at some more general trends, unrelated to lens buying. For example: how many photos did I take this year (not enough), which weekday do I most commonly shoot on (Saturday), when in the day do I normally shoot (around midday).
I’ve twice as many photos taken on Saturdays (168) as on the next closest (78, on Tuesdays??). This makes sense - I can block off a hugh chunk of weekend time to take photos in a way I can’t on a weekday. Grouping the photos by hour of the day, it looks like I take photos mostly through the middle of the day. Midday is probably the worst time to photograph: the sun is straight overhead, so generally scenery isn’t lit as interestingly. Why do I do this to myself? There are some smaller spikes around 6am and 6pm, which is probably linked to sunrise/set photography. There’s even one photo at 4am that I have no memory of.
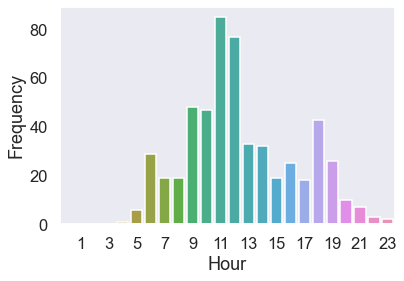
Next steps
It’d be very useful to have ratings information attached to the photos. Probably not worth going back and tagging these 500, but including it as part of the sorting process could be helpful. Not sure how to add that info to the EXIF tags, though.
I’ve learned a couple of things I can do to improve my photography:
- Get closer. Stop trying to zoom further than the lens can.
- Keep away from wide apertures unless needed for depth of field or low light.
- Leave the house earlier and get better light. Better light = better photos.
The most important next step: refer back to this post before/after buying a lens (for evidence).
The Jupyter notebook for this analysis is on Github